ShowTimeLine Hecho! Hackatón sobre visualizaciones de líneas de tiempo en @HacksHackersBA
Suggest edits
La mañana soleada del sábado 14 de abril era ideal para salir a correr. Pero en este caso no se trataba de cuerpos bien entrenados físicamente (aunque también los había) sino más bien intelectualmente preparados para un buen hackatón. Convocados por Hacks/Hackers Buenos Aires cerca de 45 personas se juntaron en Buenos Aires, Argentina, en AreaTres Soho para trabajar sobre la resolución de un problema de visualización de relaciones complejas a través de líneas de tiempos y para familiarizarse con herramientas disponibles.
En un clima muy agradable periodistas, editores de medios, del área de comunicación de algunas empresas, programadores de diferentes espacios (probablemente único espacio de este tipo en América latina) compartieron una jornada de trabajo en donde no faltaron las empanadas, bebidas y cervezas al cierre, cuando ya había que parar para elongar las ideas. Aquí se puede acceder al documento colaborativo.
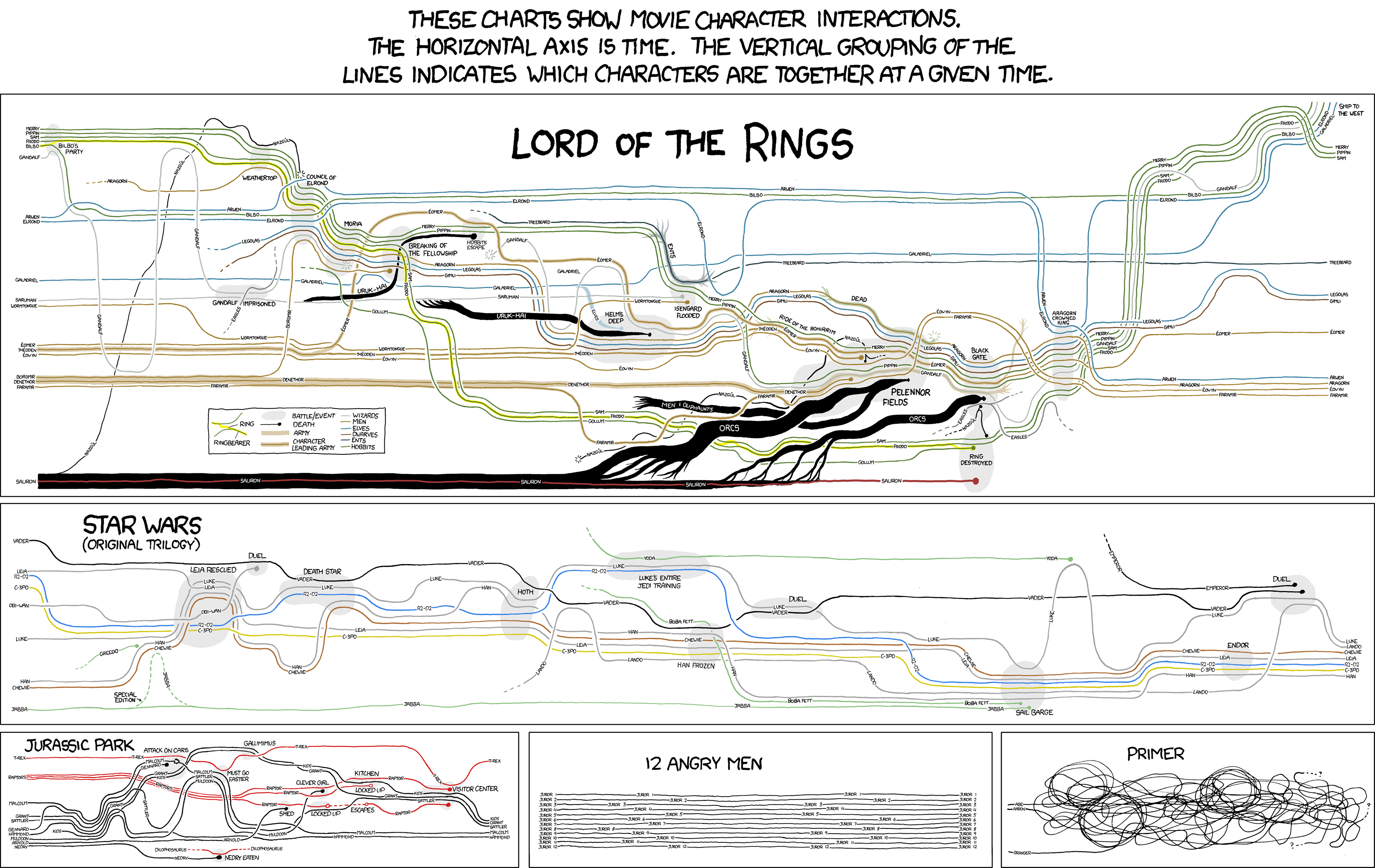
Se trabajó sobre Mapa76.info, un ambicioso proyecto de software de extracción automática de datos desde documentos de textos para su visualización en líneas de tiempo y en mapas. Malvinastreinta.com.ar, una plataforma interactiva que recrea los días de la guerra entre Inglaterra y Argentina. Trata Sexual, un proyecto de análisis periodístico y judicial sobre la trata de personas, inicialmente pensado para el caso Marita Verón. Alianzas electorales, resultados electorales vistos desde la trayectoria de partidos políticos formando y disolviendo alianzas de distrito. Y se desarrolló el prototipo de una nueva herramienta de visualización de líneas de tiempos ShowTimeLine, con la pretensión de llegar a modular el plotline de El señor de los anillos. (Este es un post colaborativo escrito por los integrantes de Hacks/HackersBA)

Luego de una pequeña explicación de la idea, Sandra Crucianelli (Fellow de la Knight Foundation) hizo una introducción a la usabilidad de las líneas de tiempo en Argentina, con una crítica fuerte a la simplicidad de sus usos y a la poca disponibilidad de herramientas de ilustración complejas. El objetivo central era realizar ingeniería inversa para lograr esta línea de tiempo de forma automática. **

**
**
Cómo se hizo ShowTimeLine!**
**
La propuesta era generar algoritmos y librerías modulares para poder ensamblar uno o varios softwares que permitan visualizar datos en líneas de tiempo complejas y otros tipos de visualizaciones posibles. La idea original fue de Andrés Snitcofsky quien desarrolló la ingeniería inversa de El Señor de Los Anillos. Finalmente, la información fue estructurada de esta manera El código desarrollado durante el hackatón se encuentra aquí: _GitHub _
Fue inicialmente pensada para resolver un problema de visibilización de relaciones complejas en el proyecto de mapa76.info. ¿Cómo podemos encontrar relaciones entre historias de vida que no podemos ver de manera “manual”? “Tiramos” las historias de vida sobre una tabla estructurada y luego observamos los recorridos. Se parte de la línea de tiempo/plotline propuesta por Randall Munroe para** **graficar la saga de _**El Señor de los Anillos.**_ Trabajaron César Miquel, Martín Sarsale, Rafa, Nicolás Cisco, Osvaldo Toja, Walter, Felipe Lerena y Martín Szyszlican.
{kind=link}

Se desmenuzó la tarea en módulos, se asignaron módulos a cada equipo, se integró con Google Docs, se generaron los datos, se graficaron usando Raphael.js, se implementaron algoritmos para la generación de la línea, se implementó en Javascript y/o Coffeescript + HTML5. Una vez realizado el prototipo de la herramienta se probó con los datos. Básicamente, se trata de una definición de cómo se deben ordenar los lugares. Una vez ingresados los datos, el sistema empieza a buscar la mejor forma de organizar la información para que las líneas se crucen lo menos posible.
Tarea pendiente, poder mejorar el filtrado, definir cercanías, atracción entre objetos, tipos de representaciones posibles, tamaños de las líneas, etc. Se puede ver el prototipo funcionando aquí ¡Prueba tu información! Por el momento no funciona muy bien (hay que seguir trabajando en los algoritmos), pero es muy divertido verlo andar. No sea malo, se hizo en apenas 10 horas de trabajo colaborativo.

Equipo de corredores: Marita Verón – Trata Sexual

Sobre una propuesta de Sergio Sorín se trabajó en el caso de Marita Verón, un conocido caso de trata sexual actualmente en juicio. Este grupo estuvo conformado también por Angélica Peralta Ramos, Gaby Bouret, Florencia Coelho y Ricardo Brom (La Nación Data), Ariel Aizemberg (Datamining UBA), Flor Bianco (Google Argentina), entre otros. Debido a que el caso Marita Verón aún está en curso, nos propusimos desarrollar un prototipo de línea de tiempo para contar el juicio.
El objetivo final es lograr una manera que éste sea alimentado desde un formulario en GoogleDocs para que en el futuro se pueda utilizar más facilmente en éste y otros casos. Un grupo se encargó de volcar una serie limitada de datos del Diario del Juicio a una tabla en Google Spreadsheet. Otro grupo se abocó a articular esos datos con el Timeline desarrollada por el Knight Media Lab y probar su funcionamiento. Realizamos la traducción de parte del código para mostrar las fechas y los controles de la navegación en español.
**

Comprobamos que el Timeline sólo funciona si se respeta los nombres de los encabezados de la columna (que no se pueden traducir). Se puede perfectamente cambiar las columnas o las filas de lugar, o incluso agregar nuevas columnas de datos, lo que no rompe el timeline.**
** Nos encontramos una serie de obstáculos a tomar en cuenta y que no están en el archivo README.markdown de instalación de timeline.verite.co**
** a) Para que los links a videos funcionen tienen que estar cargados con el link share de Youtube o vimeo y no con la URL que aparece en el navegador. **
** b) Los links cortos que redireccionan a otra web, (ejemplo bit.ly) aparecen como links rotos, por lo que es necesario mostrar la url final. El resultado del trabajo puede verse momentáneamente en este lugar.
Equipo de corredores de malvinas30 para el hackatón
**

El objetivo inicial de malvinas30 es trabajar en la línea de tiempo **
** Knight Media Labs para incorporar el contenido que están desarrollando. Hay tres periodistas trabajando en este proyecto que revive la Guerra de Malvinas como si fuera en tiempo real, pero treinta años después. Se trabajó en dos pruebas de concepto para la utilización de la herramienta adaptada al proyecto @Malvinas30. Una realizada manualmente, utilizando como input el documento con contenidos seleccionados de Twitter, Facebook, YouTube y el blog cuya versión alpha puede encontrarse aquí. Otra con desarrollo sobre Drupal para importar automáticamente los tweets de la cuenta @malvinas30 que puede encontrarse en el repositorio de Github y una primera versión en este lugar. Participaron del encuentro periodistas del trabajo interactivo malvinastreinta.com.ar, y del equipo interactivo de Todo Noticias. @cesars @alvaroliuzzi @guadalopez @eapesteguia @yaniesther @juanibelbis @dterragno @valeriaavn @soldadom30 <- este es grosso !
En ambas versiones encontramos alguna limitaciones propias del Timeline, como la imposibilidad de embeber directamente contenidos de Facebook, Ustream y otros servicios [a desarrollar(?)]. También observamos que que el volumen diario de información puede resultar contraproducente para el usuario, por lo que curar los contenidos aportaría un diferencial. También sumar contenido no publicado, exclusivo para la línea.
En la versión manual, experimentamos con los distintos formatos de organización y visualización de los contenidos. Acordamos que lo mejor sería adaptar el contenido dependiendo de la relevancia de la información: algunos tweets irían embebidos (aquellos que tuvieran sólo texto) y otros serían desarticulados para hacer énfasis en los contenidos multimedia (aquellos que tuvieran imágenes o videos).
Ideas para utilizar en una versión productiva final:
- Poder filtrar los contenidos por tipo de medio o tipo de contenido. El filtrado no está en ningún otro soporte. Hay que tener cuidado con la granularidad por la cantidad de líneas a generar. **
** 2. Filtrar más de una variable para poder comparar los contenidos en paralelo. Por ejemplo poder comparar información diaria sobre dos o más medios. **
** #ParaAvanzarSobreLaFiltracion, el equipo definió reglas de interpretación y clasificación para la filtración de contenido de Twitter en la versión Drupal. Ya que el documental es interactivo y todavía no terminó, nos permitirá, de ahora en adelante, publicar contenido adaptado a la importación de los mismos al Timeline. Están acá.
Cosas por hacer en la versión framework Drupal:
- Configurar CRON **
** 2. Persistencia en base de datos **
** 3. Configurar tipo de nodo **
** 4. Filtrar contenidos para generar múltiples líneas de tiempo
Mapa76.info De la extracción automática a la línea de tiempo y el mapa

Este proyecto de s oftware de extracción automática de datos sobre los juicios de la última Dictadura Militar nació en un hackatón realizado el año pasado en Tecnópolis. El objetivo de este proyecto es lograr una visualización automática o semi automática de historias de vidas del período 1976-1983, basada en testimonios escritos, alegatos y sentencias judiciales (aquí puede encontrar una explicación larga del proyecto) y un link al Gdoc compartido. Se trabaja sobre conceptos de big data, data mining, y web semántica. Queremos ir de la extracción de datos a la línea de tiempo para visualizar historias de vida y encontrar relaciones.

Durante el hackatón trabajó Marcos Vanetta Damian Silvani Luciana Padua Ezequiel Clerici, David Lima Cohen, Mariana Berruezo y Mariano Blejman. Es un proyecto que viene desarrollándose paralelamente desde hace varios meses, y en el hackatón se trabajó fuertemente en desarrollar conceptos de usabilidad en la extracción automática de datos, se trabajó sobre la librería Freeling (que reconoce nombres, entidades y fechas) y se agregó un módulo de detección de lugares.
Luciana Padua (datamining) trabajó en la búsqueda de ejemplos usando distintas herramientas de visualización TreeMap: http://www.cs.umd.edu/hcil/treemap/ Teniendo los datos estructurados, se puede utilizar la herramienta de treemap para agrupar los casos de las diferentes personas en distintas jerarquías. Por ejemplo: centro de detención, provincia, fecha de detención, etc. De esta forma podemos descubrir la relación de una persona con otra en función de su pertenencia a un mismo grupo. Al ser las jerarquías configurables por el usuario, se podría investigar en función de la variable de interés del investigador.
Relaciones y timeline: EDGEMAPS
Sitioweb: [http://mariandoerk.de/edgemaps/
]44 Paper: http://mariandoerk.de/edgemaps/ivj2012.pdf
Puntos en común con Mapa76.info
La herramienta permite visualizar relaciones explícitas e implícitas en dos gráficos diferentes:
_

Mapa de Similitud: Analiza la similitud entre músicos, pintores y filósofos en función de sus palabras claves. Las palabras claves son parte de la base de datos que los autores utilizaron. En nuestro caso, deberíamos definir qué utilizar como palabras claves para adaptar la visualización. Por ejemplo, definiendo como palabra clave el centro de detención, las personas que estuvieron en un mismo centro van a estar cerca en el mapa, mientras que las que no estuvieron estarán alejadas.
Timeline: En la herramienta utilizan la fecha de nacimiento de la persona para situarlo en la línea del tiempo. En nuestro caso podríamos definir fecha de detención, fecha de desaparición, etc.
Relaciones explícitas: Son modeladas como las influencias que recibe una persona y las personas en las que influyen. son explícitas porque son un dato que surge de la base. En nuestro caso a partir de la definición de la influencia podremos definir las relaciones. Por ejemplo represor-víctima.
Relaciones implícitas: Se definen en función del tiempo y las palabras claves.
Elementos de diseño: El tamaño de los nodos representa la cantidad de influencias sobre otros que tiene una persona. El color está armado en función de las palabras claves (ver paper para mayor referencia). En nuestro caso en función de lo que definamos como influencia podremos determinar la relevancia de estos elementos en el diseño.
Alianzas electorales

Andy Tow vino con su propuesta y la desarolló con sus datos. El objetivo principal de la visualización es observar la formación y disolución de alianzas distritales de partidos políticos a través del tiempo.En Argentina, los miembros del Congreso de la Nación son elegidos directamente por la ciudadanía, constituyendo cada Provincia y la Ciudad de Buenos Aires distritos electorales con su propia representación. Las agrupaciones que presentan candidatos en cada distrito son partidos y alianzas. Las alianzas son agrupaciones de dos o más partidos. Queremos mostrar la trayectoria de los partidos actuantes a nivel de distrito electoral entre 1983 y 2011 mostrando su desempeño electoral y su ingreso a y salida de alianzas y frentes electorales, como asimismo su aparición, extinción e inactividad. Se trabajó en la estructuración de la información para ser ingresada a la herramienta cuyo prototipo fue construido. **
** Se produjeron los datos para la visualización tomando la historia electoral de las provincias de Chaco y San Juan 1983-2011. A partir de los resultados de la Dirección Nacional Electoral en el Atlas de Elecciones en Argentina de Andy Tow y la información disponible sobre partidos y alianzas electorales de distrito de la Cámara Nacional Electoral, se crearon dos conjuntos de datos de la categoría Diputados Nacionales con el formato indicado por los programadores del núcleo. Elegimos estos dos distritos porque tienen un tamaño intermedio y muestran historias electorales diferenciadas, con surgimiento de terceras fuerzas electorales y formación y disolución de alianzas. Los datos fueron ingresados en una planilla disponible aquí.
Agradecemos especialmente el apoyo del programa Knight-Mozilla Open News, y de los sponsors Mozilla Foundation, Globant, LaNación.com, AreaTres, Vurbia, Página/12 y SourceFabric.
El equipo organizador de Hacks/Hackers Buenos Aires está conformado por Mariano Blejman (Página/12), Martín Sarsale (Sumavisos), Guillermo Movia (Mozilla Argentina), César Miquel (Easytech), Mariana Berruezo, Sergio Sorin, Ezequiel Clerici y Andrés Snitcofsky.
twitter @HacksHackersBA
mail ba@hackshackers.com
Web http://meetupba.hackshackers.com
blog http://www.hackshackers.com
local blog http://hhba.info